Bits, bytes, and encodings
I wrote this post sometime last year. Now that theviewfromjq.com is up and running, I'm sharing it from the vault!
Learning about bits, bytes, characters and encodings can seem intimidating, especially when it comes to their relationships with one another. For those who don't have a formal computer science background, myself included, it can be a challenge to retain even basics, especially when the practically relevant information we need is often just a Google search away.
Still, there is no substitute for deeper comprehension. The other day I spent a few hours drawing out diagrams to better illustrate these concepts to myself, only to find that they're not so hard, after all! I feel much more confident in my mastery over bits, bytes, characters, encodings and more.
Here's what I learned:
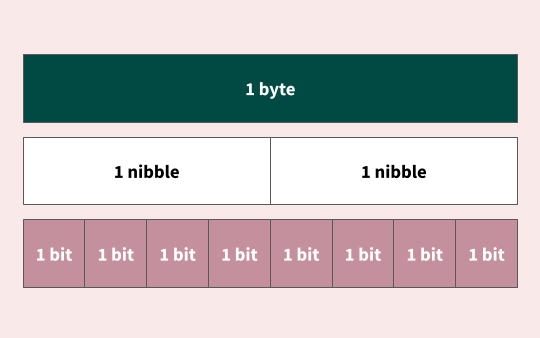
How many bits are in a byte?

Why can 1 byte hold 256 different values?

Each bit stores exactly two distinct states: 0 or 1. Conceptually, this is similar to an electrical switch, which can either be on or off.
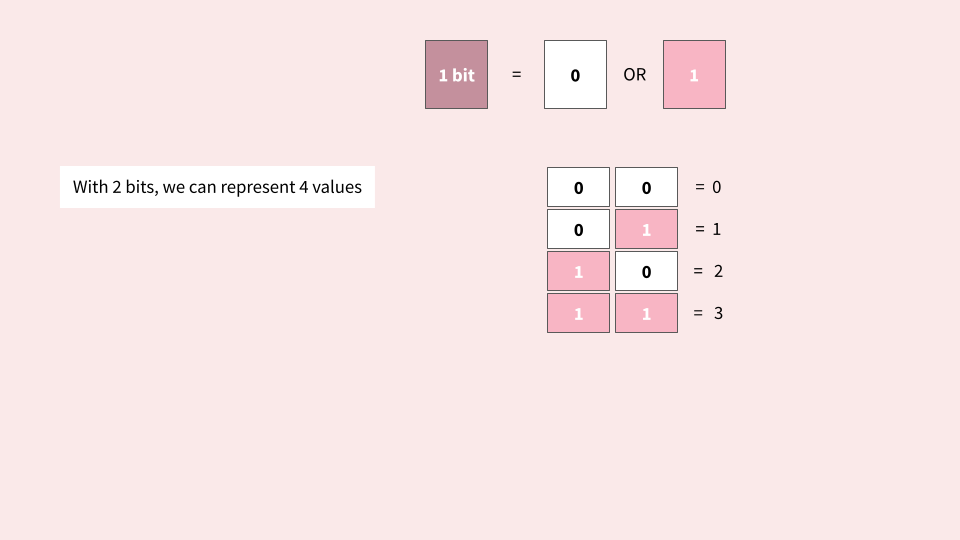
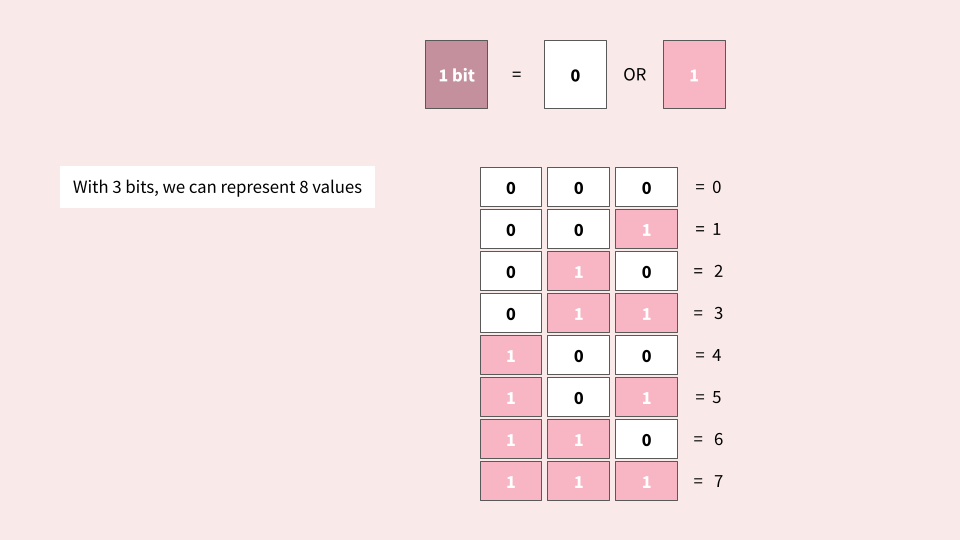
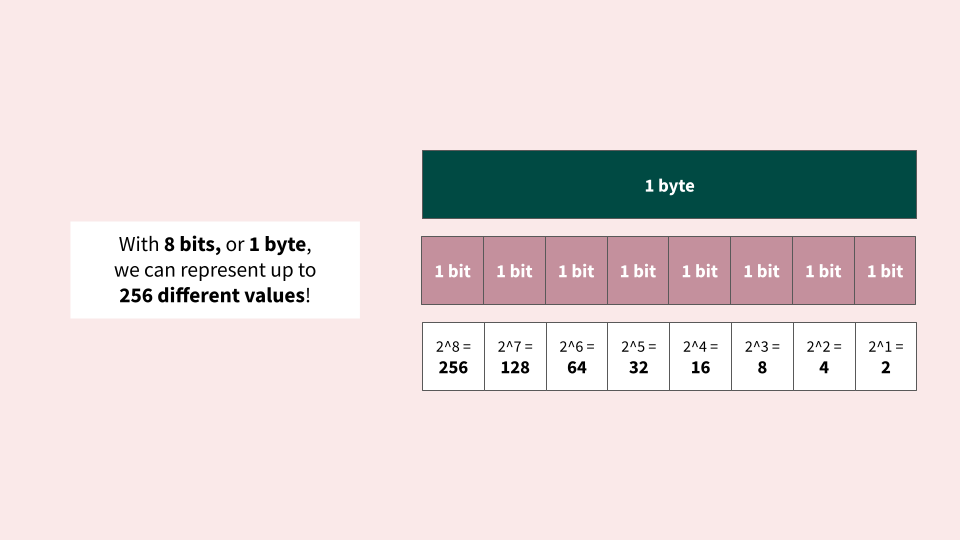
As you can see, with 1 byte, we can represent up to 256 values! This could be the numbers 0-255 if we only wanted to represent non-negative integers. Alternatively, it could be the numbers -128 to 128, if we wanted to represent signed integer. It could even be 256 random characters! See the ASCII section below as an example.
How do I represent numbers in binary?
In our everyday lives, we are used to see numbers represented using the base-10 notation:
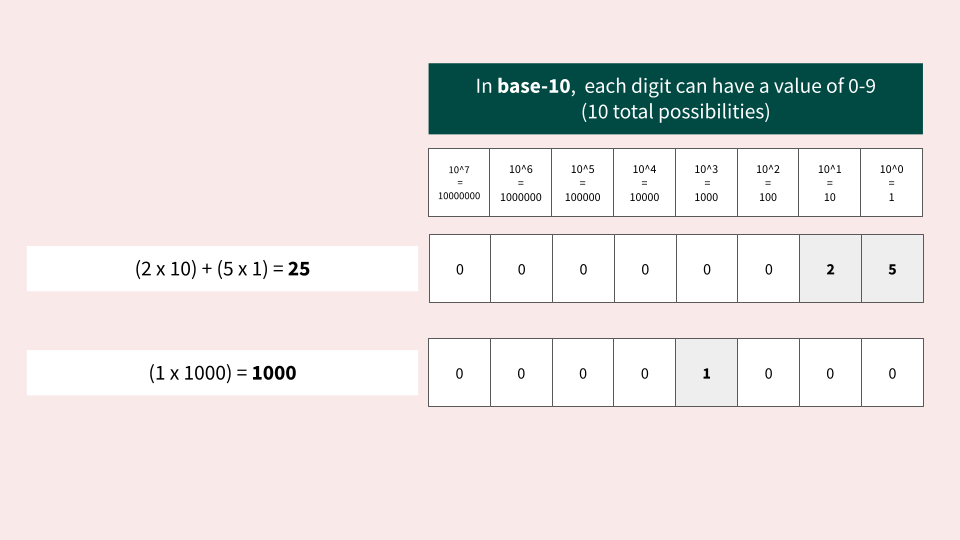
When working with bits and bytes, numbers need to be represented using a base-2 notation, also known as binary:
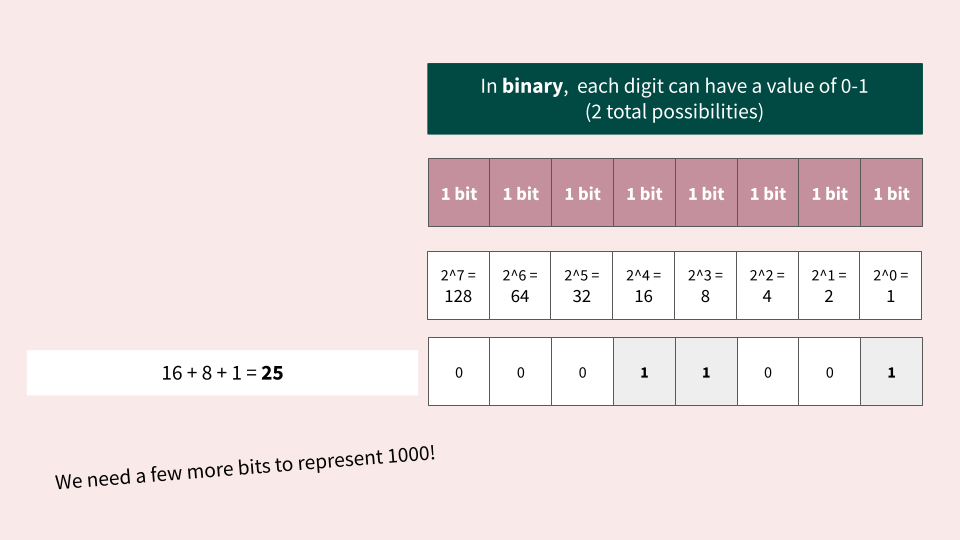
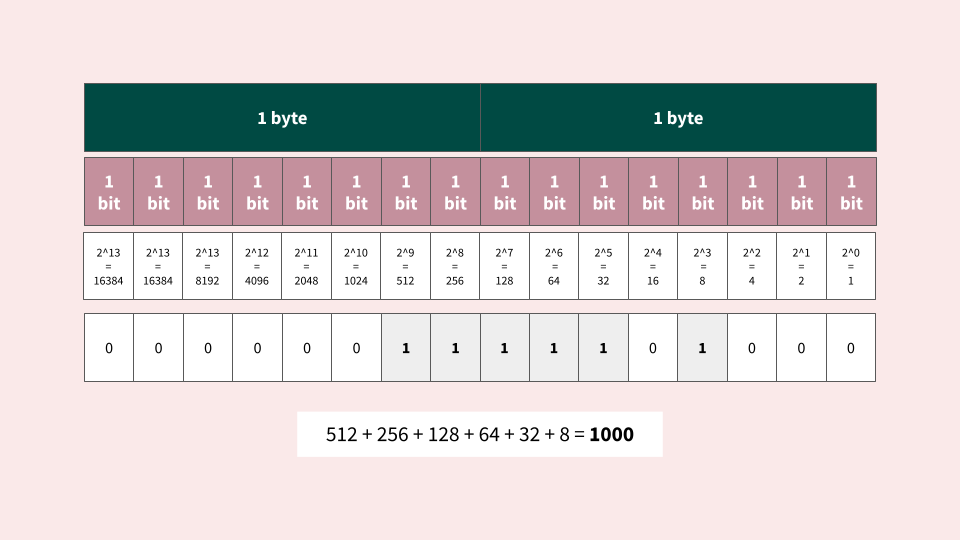
How do I represent the number 1000 in binary?
Remember that 255 is the largest number we can represent with 1 byte. However, 2 bytes, we can represent up to 65,535.
Bits and bytes are the foundational unit for how information is stored on a computer. Your next question might be:
Where do we see bits and bytes in everyday software engineering?
ASCII
Back in the old days, the only characters that mattered for computer programming were unaccented English letters, which were coded in ASCII, the American Standard Code for Information Interchange.
ASCII uses 1 byte to represent characters (Originally it used 7-bit encoding and had 128 values):
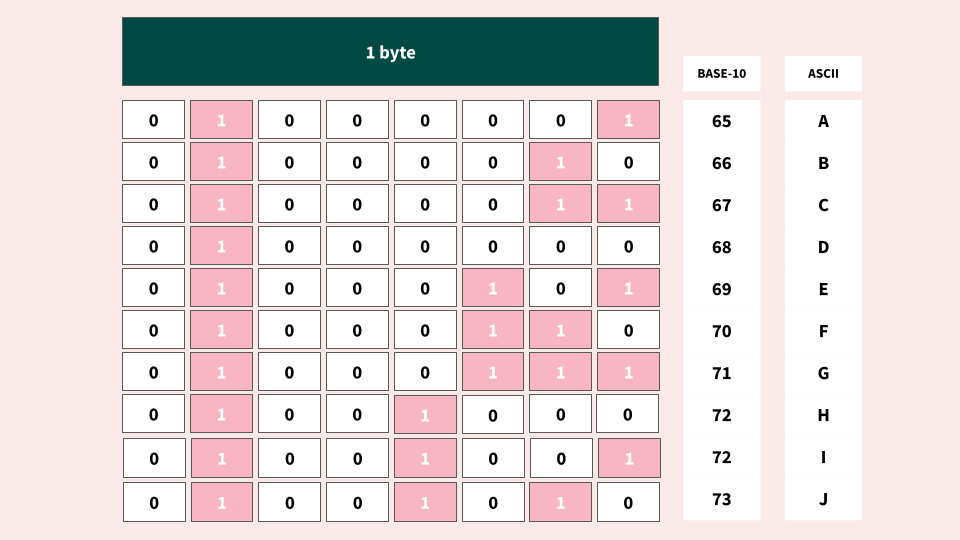
The first 32 characters (0-31) are non-printable control codes. The last 95 characters (32-127) are letters, digits, and symbols used in the English language. The diagram above shows the characters A-J, which correspond with 65-73. See the full ASCII table for details.
Unicode
While ASCII works for English speakers, the extra remaining bit doesn’t leave a lot of room for other languages. Asian alphabets, for example, can have thousands of characters. Emojis are also an important part of everyday expression.
Unicode (a universal character encoding standard) uses 4 bytes to enable many more characters to be represented. 4 bytes = 32 bits, which gives us roughly 4 billion values (4,294,967,296 exactly). The standard includes about 100,000 characters.
Specifically in the Go programming language, a rune is the data type that stores Unicode characters. Runes use 4 bytes for storage (or 32 bits, hence making it an int32 equivalent) and are used to represent Unicode characters, encoded in UTF-8 format.
UTF-8
UTF (Unicode Transaction Format) defines how Unicode is represented in code. UTF-8 is the most common method and is compatible with ASCII. While Unicode uses 4 bytes, not every character requires 4 bytes to be represented, so UTF-8 helps to compress this information. Specifically, it reduces characters to the following:
- 1 byte to represent English letters and symbols.
- This means that English text looks exactly the same in UTF-8 as it does for ASCII!
- 2 bytes to represent additional Latin and Middle Eastern letters and symbols.
- 3 bytes to represent Asian letters and symbols.
- 4 bytes for other additional characters.
Hopefully you understand bits and bytes a little better! To learn more, see the references below.